
Quick Summary:
Getting started with sentiment analysis Python? Look into the Sentiment analysis. Python libraries like NLTK, TextBlob, and VADER provide pre-trained models, simple APIs, and specialized functionality for analyzing sentiments in textual data. These top Python libraries for sentiment analysis make it easy for beginners to start with this important natural language processing technique.
In this digital age, organizations need to know the opinion of people. Monitoring these opinions gives an insight about customer’s likes and dislikes. This helps organisations launch or even promote their products in the way people prefer. However, it is essential to keep in mind that this data is in enormous amount. This where sentiment analysis comes to play. Let’s see what is sentiment analysis?
Sentiment analysis, also known as opinion mining, is an increasingly crucial natural language processing (NLP) technique for determining emotional tone, subjectivity, and opinions within textual data. It involves using algorithms and models to classify sentiments expressed in documents, social media posts, reviews, and other text sources as positive, negative, or neutral. Thanks to its extensive libraries and flexible functionality, Python has become a popular language for sentiment analysis NLP.
Several robust Python libraries are available for performing sentiment analysis on textual data, including NLTK, TextBlob, VADER, and more. These libraries provide pre-trained sentiment analysis models, lexicons, intuitive APIs, and specialized features tailored to analyse text sentiments and opinions.
This blog post will explore some of the top Python libraries for sentiment analysis, including the popular NLTK library, which contains tools for building sentiment classifiers using machine learning algorithms. We will look at the key features and advantages of using these Python libraries to make sentiment analysis accessible and effective, even for beginners looking to get started with NLP-based text analysis and opinion mining.
Let’s understand the importance of selecting the proper python sentiment analysis library before diving into sentiment text analysis Python.
The Significance of Selecting Appropriate Python Sentiment Analysis Libraries
Sentiment analysis is a vital tool for interpreting & comprehending the emotional undertone and arbitrary viewpoints in text analysis Python using NLP sentiment analysis. These Python sentiment analysis libraries provide the utmost support to an ai-driven sentiment analyzer. The process of NLP sentiment analysis can impact the terms of accuracy, effectiveness, and overall success.
In our exploration, we’ll dive into a collection of exceptional resources that empower sentiment analysis in Python. These sentiment analysis libraries not only decode emotional subtleties embedded in text but also align with Python best practices, ensuring improved precision and efficacy in AI-powered sentiment analysis. Join us as we unveil the most outstanding contenders among the Sentiment Analysis Python Packages & Libraries selection.
Top Sentiment Analysis Python Packages & Libraries
By harnessing the potential of these advanced libraries, you can magnify the influence of your sentiment analysis initiatives, refining their precision and playing a role in the triumph of your overall project. Let’s see the specially curated list of sentiment analysis Python.

TextBlob
GitHub Star: 8.7K | Fork: 1.1K | Licence: MIT
First one on the list of sentiment analysis python library is TextBlob. It is a Python library used to analyze textual data and carry out typical operations related to natural language processing, such as part-of-speech tagging, noun phrase extraction, sentiment analysis, classification, translation, and more. By representing documents as convenient to handle TextBlob objects, it offers a straightforward API for getting started with NLP.
Built on top of NLTK and Pattern, TextBlob inherits a lot of NLP functionality from those libraries. Its simplified sentiment analysis based on pattern’s word polarity detection is a key feature. TextBlob supports multiple languages and is well-documented, making it suitable for beginners and experts alike. Overall, TextBlob aims to provide an accessible Python interface for common NLP tasks on textual data.
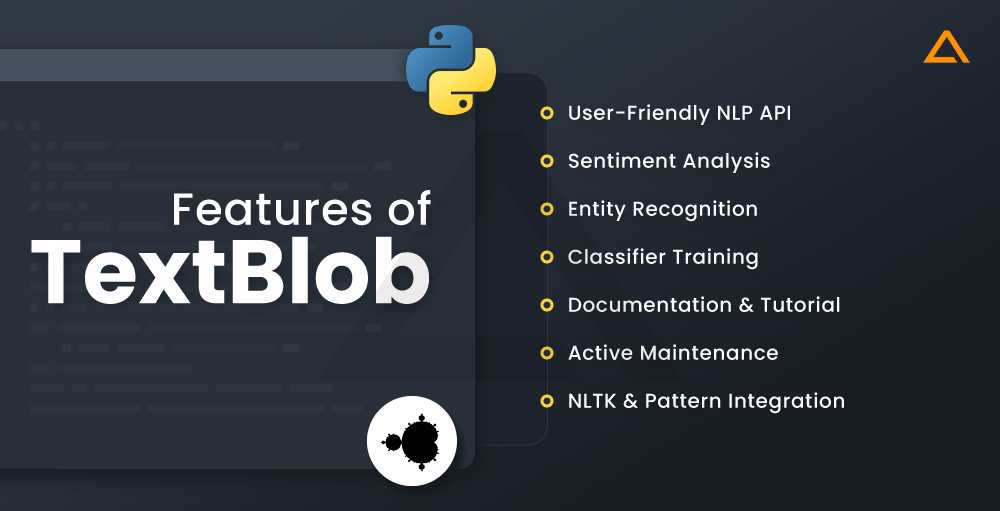
Features of TextBlob
- User-Friendly NLP API
- Sentiment Analysis
- Entity Recognition
- Classifier Training
- Documentation & Tutorial
- Active Maintenance
- NLTK & Pattern Integration
TextBlob Use Cases
- Sentiment Analysis
- Text Summarization
- Spell Checking & Correction
- Language Translation
- Keyword extraction
- Part-of-speech tagging
- Text Classification
Example of Textblob
from textblob import TextBlob
text = "The movie was excellent! Acting was great and the story was engaging."
blob = TextBlob(text)
sentiment = blob.sentiment
if sentiment.polarity > 0:
print("Positive sentiment")
elif sentiment.polarity == 0:
print("Neutral sentiment")
else:
print("Negative sentiment")
print(f"Polarity: {sentiment.polarity}")
print(f"Subjectivity: {sentiment.subjectivity}")Output
Positive sentiment
Polarity: 0.475
Subjectivity: 0.725Vader
GitHub Star: 4.1K | Fork: 975| Licence: MIT
A tool for sentiment analysis using a vocabulary and rules is called VADER, which stands for Valence Aware Dictionary and Sentiment Reasoner. Optimized specifically for analyzing sentiment in social media text. It works by using a vocabulary of words that have been manually labeled as positive or negative.
When analyzing text, VADER checks which sentiment words are present and applies rules around sentiment intensity and grammar to determine an overall compound sentiment score between -1 and 1, with positive scores indicating positive sentiment.
The advantages of VADER sentiment analysis are that it is tuned for informal social media language, efficient for large volumes of text, and accurate when the lexicon matches vocabulary. VADER sentiment provides fast and robust analysis capabilities for social media monitoring applications by leveraging a pre-labelled sentiment lexicon and heuristics.
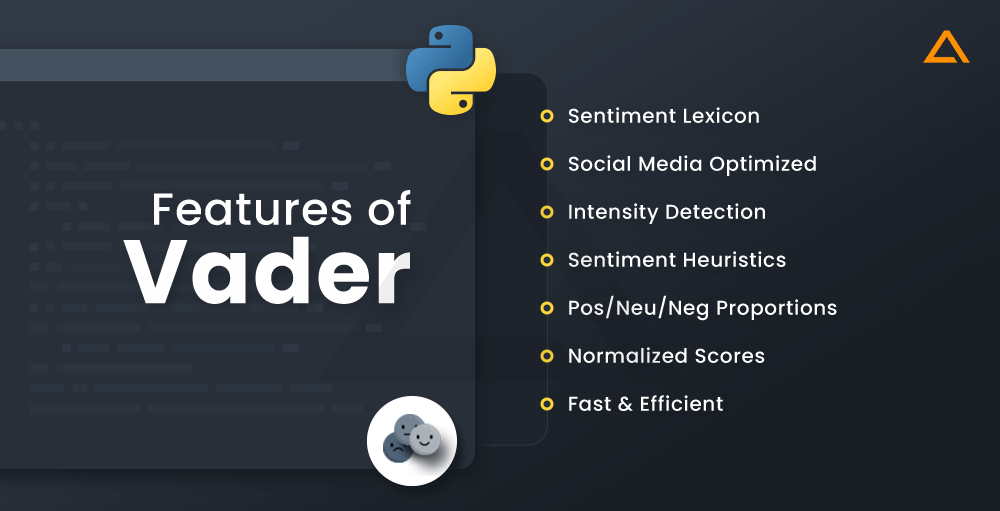
Features of Vader
- Sentiment lexicon
- Social media optimized
- Intensity detection
- Sentiment heuristics
- Pos/Neu/Neg proportions
- Normalized scores
- Fast and efficient
Use cases of Vader
- Social Media Monitoring
- Review Analysis
- Chatbots
- Customer Service
- Market Research
- Content Moderation
- Writing Assistance
Example of Vander
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
text = "The movie was excellent! Acting was great and story was engaging."
scores = analyzer.polarity_scores(text)
print(scores)Output
{'neg': 0.0, 'neu': 0.512, 'pos': 0.488, 'compound': 0.4404}NLTK
GitHub Star: 12.4 K | Fork: 2.8K | Licence: Apache-2.0
NLTK sentiment analysis or Natural Language Toolkit is an open-source Python platform for building programs for tasks involving natural language processing that use human language data. It provides extensive libraries, interfaces to corpora and resources like WordNet, and a suite of text processing libraries for classification, tokenization, parsing, semantic reasoning and more.
NLTK combines simplicity, ease of use and breadth across symbolic and statistical NLP. It has extensive documentation and is widely used in both academia and industry for research and applications including sentiment analysis, chatbots, summarization and more. NLTK has established itself as a leading platform and the most widely used toolkit for natural language processing in Python due to its breadth, development vitality and vibrant community support.
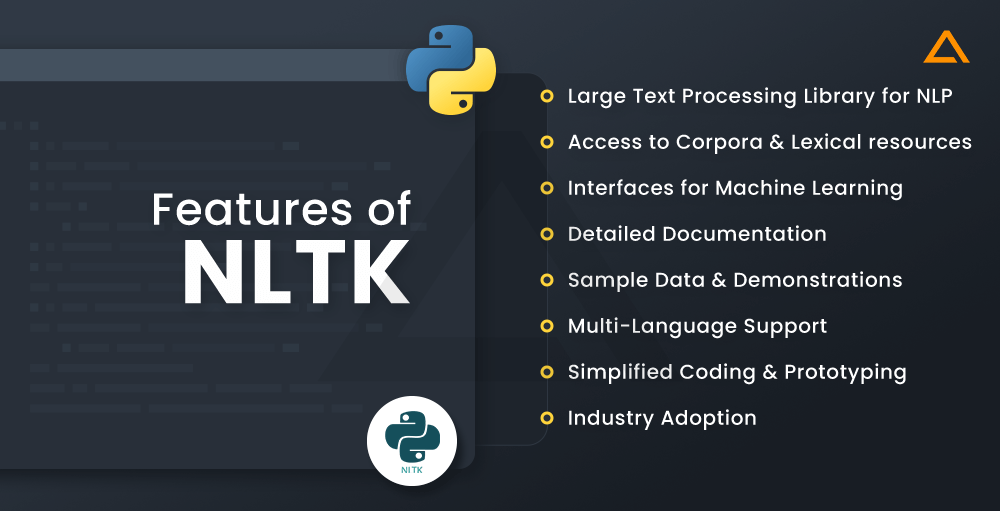
Features of NLTK
- Large text processing library for NLP
- Access to corpora and lexical resources
- Interfaces for machine learning
- Detailed documentation
- Sample data and demonstrations
- Multi-language support
- Simplified coding and prototyping
- Industry adoption
Use cases of NLTK
- Sentiment Analysis
- Machine translation
- Documentation Classification
- Chatbots
- Speech Recognition
- Topic Modeling
- Spam Detection
- Grammatical Analysis
Example of NLTK
import nltk
from nltk.sentiment import SentimentIntensityAnalyzer
text = "The film was excellent! Acting was great and story was engaging."
analyzer = SentimentIntensityAnalyzer()
scores = analyzer.polarity_scores(text)
print(scores)Output
{'neg': 0.0, 'neu': 0.254, 'pos': 0.746, 'compound': 0.6369}Hey!
Are you Looking to Hire Python Developer?
Hire a dedicated team from Aglowid for high-quality python developers who are equipped with the latest Python skill-sets
BERT
GitHub Star: 35.3 K | Fork: 9.4K | Licence: Apache-2.0
In 2018, Google created the ground-breaking NLP sentiment analysis technique, BERT (Bidirectional Encoder Representations from Transformers). It uses a deep learning model called Transformers and pre-training on massive text corpora to generate representations of language that capture bidirectional context and attention-based interactions between words.
BERT can acquire significantly richer semantic and contextual comprehension as a result, distinguishing itself from earlier unidirectional, recurrent NLP models. In order to develop cutting-edge models for a variety of NLP tasks, from question answering to sentiment analysis, a pre-trained BERT model can then be fine-tuned with minimal task-specific alterations. BERT has significantly advanced numerous NLP challenges and served as inspiration for subsequent transformer architectures thanks to key advantages including bidirectionality, attention mechanisms, and self-supervised pre-training.
Features of BERT
- Transformer architecture
- Bidirectional training
- Massive pre-training
- Learns contextual relations
- Rich representations
- Minimal fine-tuning
- Cutting edge performance
- Deep understanding
- Model size options
- Inspired extensions

Use cases of BERT
- Question Answering
- Natural Language Inference
- Sentiment Analysis
- Named Entity Recognition
- Keyword Extraction
- Text Generation
- Poetry Generation
- Spam/Offense Detection
Example of BERT
from transformers import AutoModelForSequenceClassification
from transformers import TFAutoModelForSequenceClassification
from transformers import AutoTokenizer
import numpy as np
# Load pre-trained BERT model and tokenizer
model = TFAutoModelForSequenceClassification.from_pretrained("nlptown/bert-base-multilingual-uncased-sentiment")
tokenizer = AutoTokenizer.from_pretrained("nlptown/bert-base-multilingual-uncased-sentiment")
# Define text
text = "I really enjoyed this movie! It was great."
# Tokenize and encode text
encoded_input = tokenizer(text, return_tensors='tf')
# Pass input to model
output = model(encoded_input)
# Take softmax of output
scores = np.softmax(output[0].numpy(), axis=1)
# Print sentiment scores
print("\nPositive:", scores[0][2])
print("Negative:", scores[0][1])Output
Positive: 0.99755683
Negative: 0.00244317SpaCy
GitHub Star: 27.2K | Fork: 4.3K | Licence: MIT
SpaCy is an advanced open-source natural language processing library for Python. It provides high-performance NLP analysis, with an emphasis on ease-of-use and production readiness. SpaCy combines fast syntactic parsing, named entity recognition, document similarity and multilingual support into one unified library. It integrates seamlessly with deep learning frameworks for developing neural network models.
SpaCy is designed to help build applications that understand the text and deliver insights. The library provides pre-trained statistical models for significant languages, visualizers, and a straightforward API for everyday tasks. Written in optimized Cython code, SpaCy handles large volumes of text efficiently. It has detailed tutorials, docs, and community support.
SpaCy is widely used in industry applications and fast prototyping by startups. With its usability, performance, and extensibility combination, SpaCy is a leading Python NLP library for building production-ready NLP applications.
Features of SpaCy
- Multilingual support
- Deep learning integration
- End-to-end pipelines
- Intuitive API
- Data interoperability
- Informative visualizers
- Loadable pipelines

Use cases of SpaCy
- Name Entity Recognition
- Text Classification
- Sematic Search
- Dependency Parsing
- Language Detection
- Sentiment Analysis
- Part of Speech Tagging
Example of SpaCy
import spacy
from spacytextblob.spacytextblob import SpacyTextBlob
# Load en_core_web_sm model
nlp = spacy.load('en_core_web_sm')
# Add TextBlob to spaCy pipeline
nlp.add_pipe('spacytextblob')
text = "I really enjoyed this movie! It was great."
doc = nlp(text)
# Get polarity and subjectivity
polarity = doc._.blob.polarity
subjectivity = doc._.blob.subjectivity
print("Polarity:", polarity)
print("Subjectivity:", subjectivity)Output
Polarity: 0.675
Subjectivity: 0.85Is Sentiment Analysis Supervised or Unsupervised Learning?
Sentiment analysis typically falls under the realm of supervised learning. In this scenario, the machine learning model is trained on labeled data, where text entries are tagged with their corresponding sentiments, which could be positive, negative, or neutral. Through this training, the model grasps patterns, and cues to forecast the sentiment of new, unseen text.
In contrast, unsupervised learning involves a different approach. Here, the model isn’t provided with labeled data; instead, it autonomously uncovers patterns and connections within the data. Unsupervised learning methods, often employed for tasks like clustering, focus on grouping data points based on shared traits rather than predicting predefined labels.
Analyzing sentiment can pose difficulties as it entails grasping textual context and nuances, demanding comprehension of language and human sentiments. This complexity is why sentiment analysis is commonly tackled through supervised learning, involving training the model with labeled text instances for learning.
Things to Consider When Choosing a Python Sentiment Analysis Library
Due to its rich ecosystem of libraries and tools Python offers several ways of sentiment analysis. However, the applicability of a particular library depends on several variables that should be carefully considered. Here’s why choosing Python sentiment analysis modules carefully is so important:
- Performance & Accuracy
- Adaptability & Customization
- Integration & Ease of use
- Resource Efficiency & Scalability
- Robust Community Support

Performance & Accuracy
- Benchmark accuracy on datasets like your use case. Accuracy can vary across tools
- Evaluate speed, latency, and throughput especially for real-time or large-scale analysis
- Look for optimizations like multi-threading support for faster analysis
Adaptability & Customization
- Ability to tailor models, dictionaries, stop word lists for your text domain
- Tools that allow training custom classifiers are more adaptable
- Open-source libraries with extendable architectures are easier to customize
- Check for support of different techniques like lexicon, ML, DL etc
Integration & Ease of Use
- Clean and intuitive APIs make the library easier to learn and use
- Support for integration into different apps/systems like Python, Spark, Hadoop etc
- Look for detailed documentation, tutorials, community answers
- Consider end-to-end ease of installation, training, deployment
Resource Efficiency & Scalability
- Memory usage and computational needs should fit your deployment environment
- Ability to scale out across multiple CPU/GPUs for large volumes of data
- Cloud hosted APIs can provide scalability without infrastructure concerns
Robust Community Support
- Mature libraries have robust communities for answers and contributions
- Check for responsiveness on forums, chat, GitHub issues etc
- Engaged communities enable active development and maintenance
Have a Unique App Idea?
Hire Certified Developers To Build Robust Feature, Rich App And Websites.
Wrapping Up!
This brings us to the end of best sentiment analysis library python. Python offers a diverse landscape of python sentiment analysis library for implementing sentiment analysis solutions with each library using different techniques and having unique strengths. When evaluating options of best Python Frameworks & Libraries for sentiment analysis, critical criteria to consider are accuracy on real-world data, speed and scalability needs, ease of use and integration, ability to customize, and community support. Libraries like TextBlob provide simple APIs to get started, SpaCy and NLTK offer production-level capabilities, and VADER delivers optimized social media analysis.
Trying multiple options can help determine the best fit based on factors like intended use cases, efficiency needs and customizability for a given project. Overall, Python sentiment analysis libraries powered by vibrant open-source communities equip beginners and experts to find optimized solutions tailored to their requirements.



 Say
Say